package help.lixin.lucene.service;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.DoublePoint;
import org.apache.lucene.document.IntPoint;
import org.apache.lucene.document.LongPoint;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.StoredField;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.Before;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer;
import help.lixin.lucene.dao.IProductDao;
import help.lixin.lucene.dao.impl.ProductDaoImpl;
import help.lixin.lucene.model.Product;
public class IKAnalyzerTest {
@Test
public void testIKAnalyzer() throws Exception {
// 2. 创建文档对象
Document document = new Document();
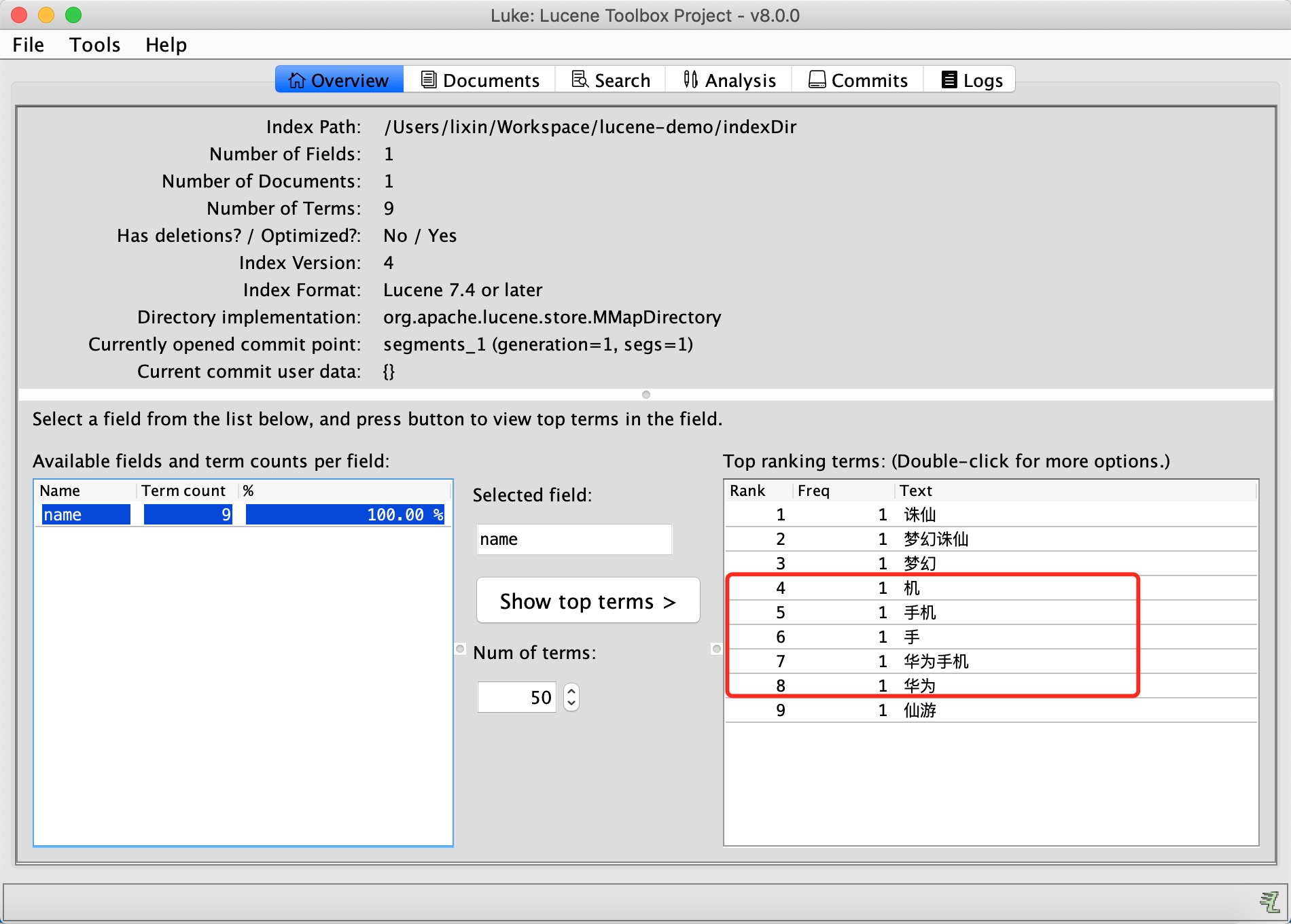
document.add(new TextField("name", "梦幻诛仙 梦幻仙游 诛仙 华为手机", Store.YES));
// 3. 创建分词器(标准分词器,对英文分词效果后,对:中文是单字分词)
Analyzer analyzer = new IKAnalyzer();
// 4. 创建索引库存放目录
String indexDir = "/Users/lixin/Workspace/lucene-demo/indexDir";
Directory directory = FSDirectory.open(Paths.get(indexDir));
// 5. 创建IndexWriterConfig,指定:分词器
IndexWriterConfig config = new IndexWriterConfig(analyzer);
// 6. 创建IndexWriter,指定:索引目录和中文分词器
IndexWriter writer = new IndexWriter(directory, config);
// 7. 写入文档
writer.addDocument(document);
// 8. 释放资源
writer.flush();
writer.close();
}
}