(1). Field属性
是否索引
是 : 进行索引,即将Field分词后的词汇或整个Field Value建立索引,在Lucene中,只有建立了索引的数据,才能进行检索.所以:索引的目的是为了搜索.
比如:商品名称,商品描述分析后进行索引,而,订单号,身份证号码不用分词,但是,需要索引,因为,将来要根据这些域进行条件查询.
否: 不索引
是否分词(tokenized)
是: 即将Field值进行分词过程,分词的目的是为了索引(支持模糊检索).
比如:商品名称,商品描述,这些内容用户要输入关键字搜索.所以,需要对其进行分词转换成词汇(建立索引).
否: 即对Field不进行分词处理.
比如:商品ID,价格,身份证号码等等.
是否存储
是: 即将Field Value序列化.
比如:商品名称,订单号,凡是将来要从Document中获取的Field都要存储.
否: Field Value不进行序列化(不持久化)
比如: 商品描述,内容较大不用存储,如果向用户展示描述,则可以从HBase这类型的数据库中获取.
(2). Field常用类型
参考( https://blog.csdn.net/alex_xfboy/article/details/83184319 )
(3). 总结
# TextField默认情况下:
# 是否分词: Y
# 是否索引: Y
# 是否存储为: N
document.add(new TextField("pname", String.valueOf(product.getPname()), Store.NO));
Luke查看数据结构
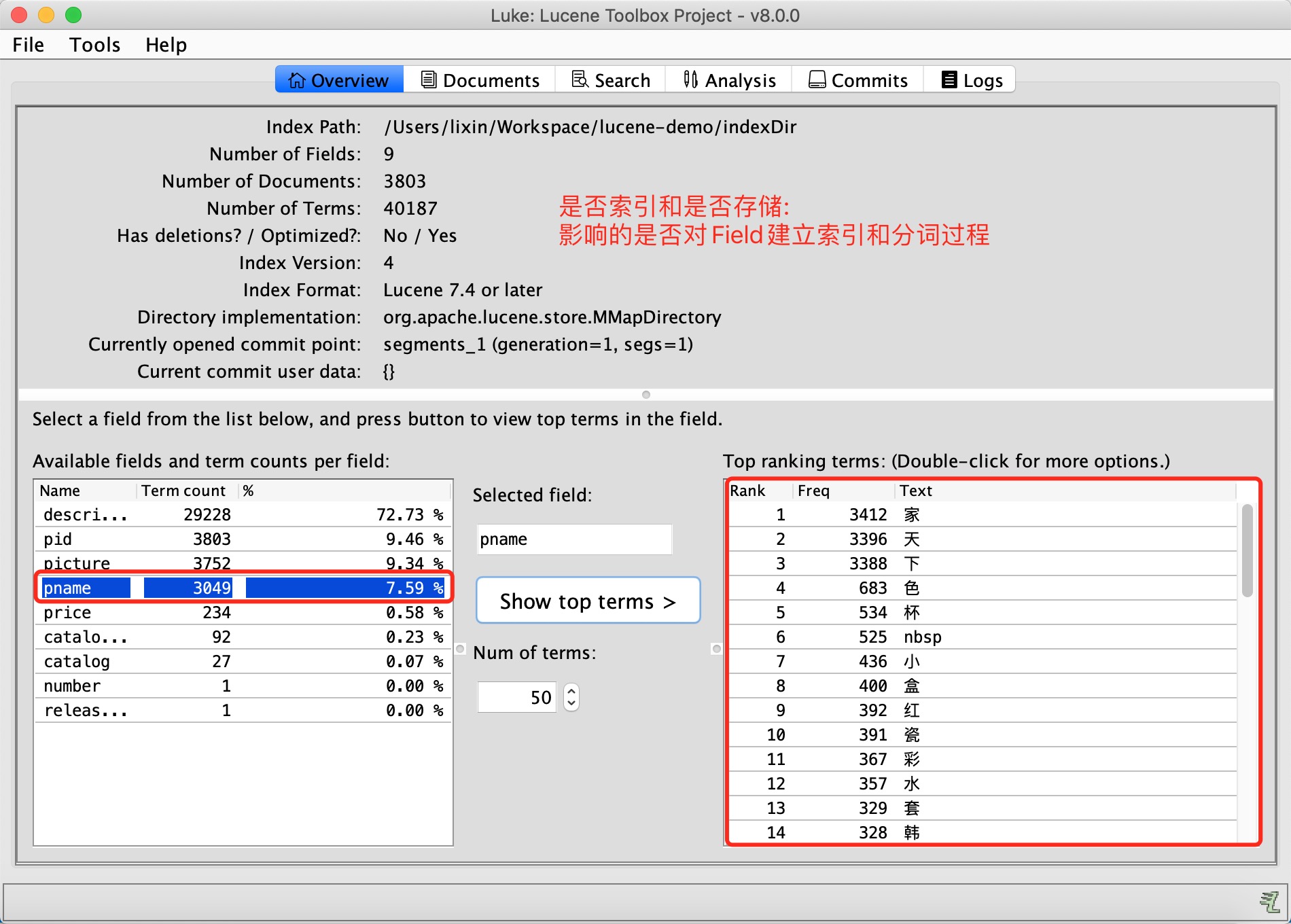
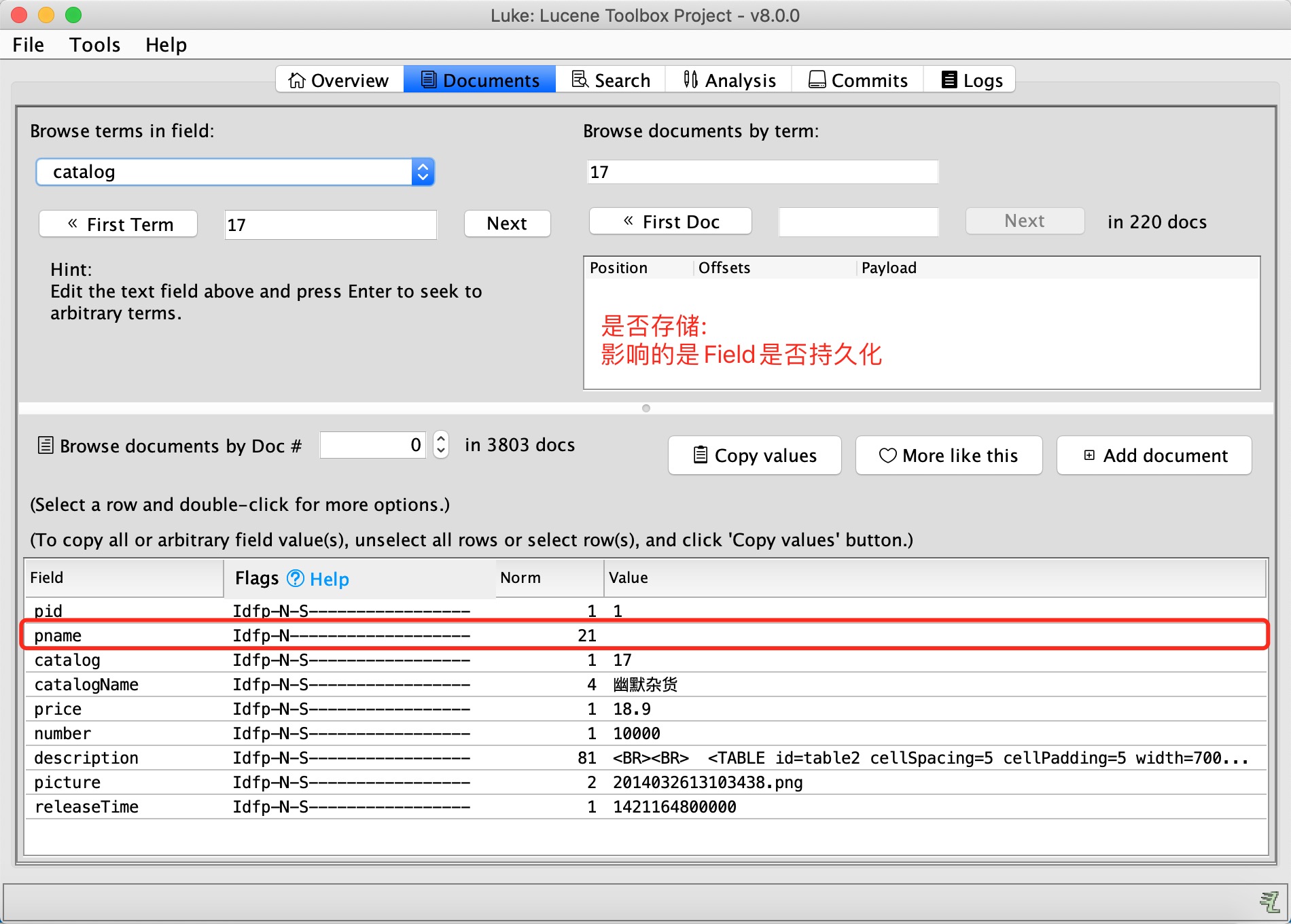
总结:
一句话总结:是否存储影响Field持久化.是否索引和分词,影响的是Field能否进行建立索引和分词.
由于配置了(索引和分词),所以,对该Field是可以进行检索(模糊检索),同时,因为:配置了不存储,所以,Document里该Field Value为空(Field Value不参与持久化).
