(1). Hadoop由来
Hadoop最早起原于Nuth,Nuth的设计目标是构造一个大型的全网搜索引擎,包括:网页抓取,索引,查询,可是,随着数据的增加,数据的存储和索引遇到了严重的问题.
2003年,2004年谷歌发表了的两篇论文为该问题提供了可行的解决方案.
分布式文件系统(GFS),可用于处理海量网页的存储.
分布式计算框架MapReduce,可用于处理海量网页的索引计算问题.
Nuth的开发人员完成了相应的开源实现HDFS和MapReduce,并从Nuth中分离出独立的Hadoop项目.
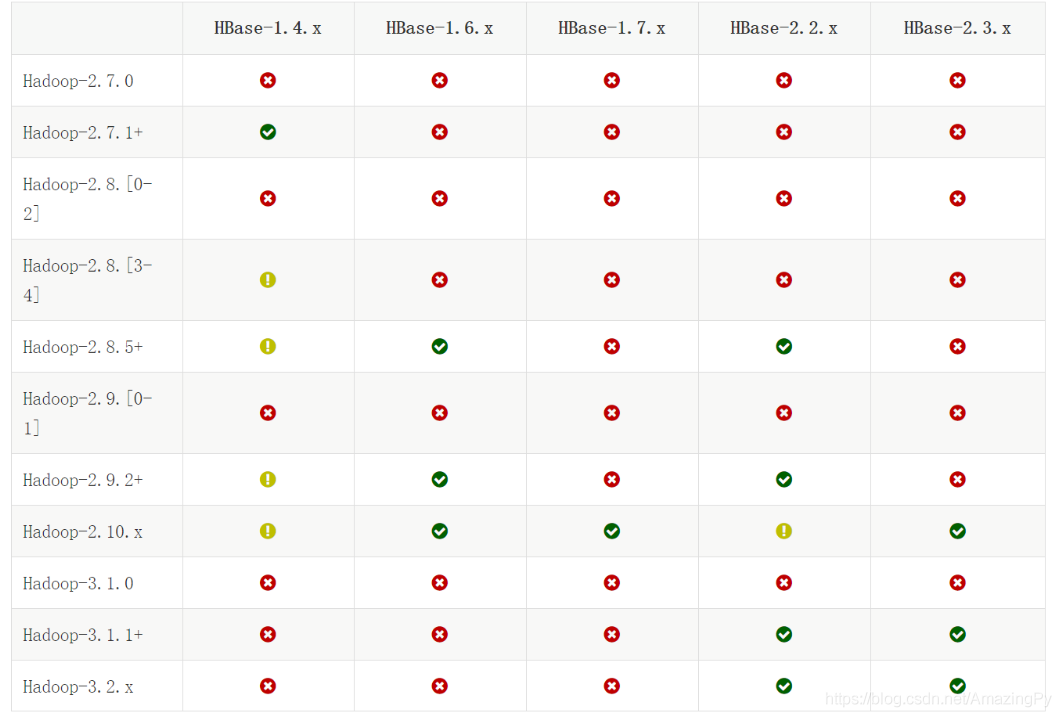
(2). Hadoop和HBase对应的版本