(1). HDFS介绍
随着互联网的兴起,现代的企业中,单机容量无经无法存储大量数据,需要跨机器存储,并期望统一管理分布式集群中的文件系统称为:分布式文件系统.
HDFS,是Hadoop Distributed File System的简称,它非常适合存储大型数据(比如:TB和PB).那么HDFS到底是什么呢?其实,可以把HDFS看成一个抽象的文件存储系统,它使用多台计算机存储文件,并且提供统一的访问接口,像是访问一个普通的文件系统一样使用分布式文件系统.
(2). HDFS架构
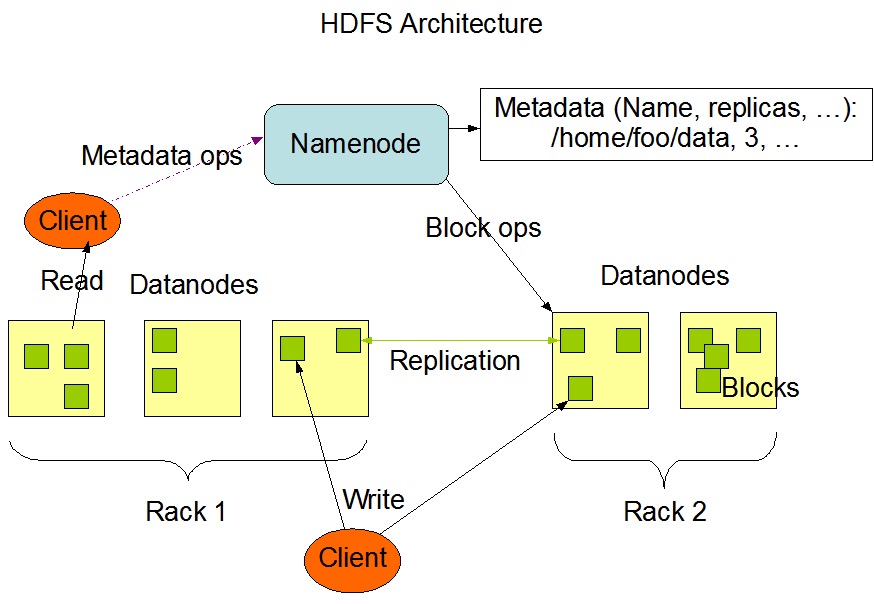
(3). NameNode
NameNode是集群中的元数据节点,负责管理:元数据(文件大小/文件位置/文件权限),数据块(Block)映射信息,配置副本策略,并且处理客户端读写请求.
NameNode在内存中保存着整个文件系统的名称空间和文件数据块的地址映射,在整个HDFS可存储的文件数受限于:NameNode的内存大小.
(4). SecondaryNameNode
SencodaryNameNode主要用于Hadoop当中元数据信息的辅助管理. SecondaryNameNode并不是NameNode的热备,当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务.
它的主要作用是辅助NameNode,分担其工作量,定期合并fsimage和fsedits并推送给Namenode.在紧急情况下,可辅助恢复NameNode.
(5). DataNode
DataNode是集群中的数据存储节点,主要用于存储实际的数据块和执行数据块的读写操作.
(6). Client
Client作用
文件上传到HDFS的时候,Client会将文件切分成一个一个的Block,然后进行存储.
从NameNode获取文件的位置信息.
将数据读取或写入到DataNode.
提供一些命令来管理和访问HDFS.
