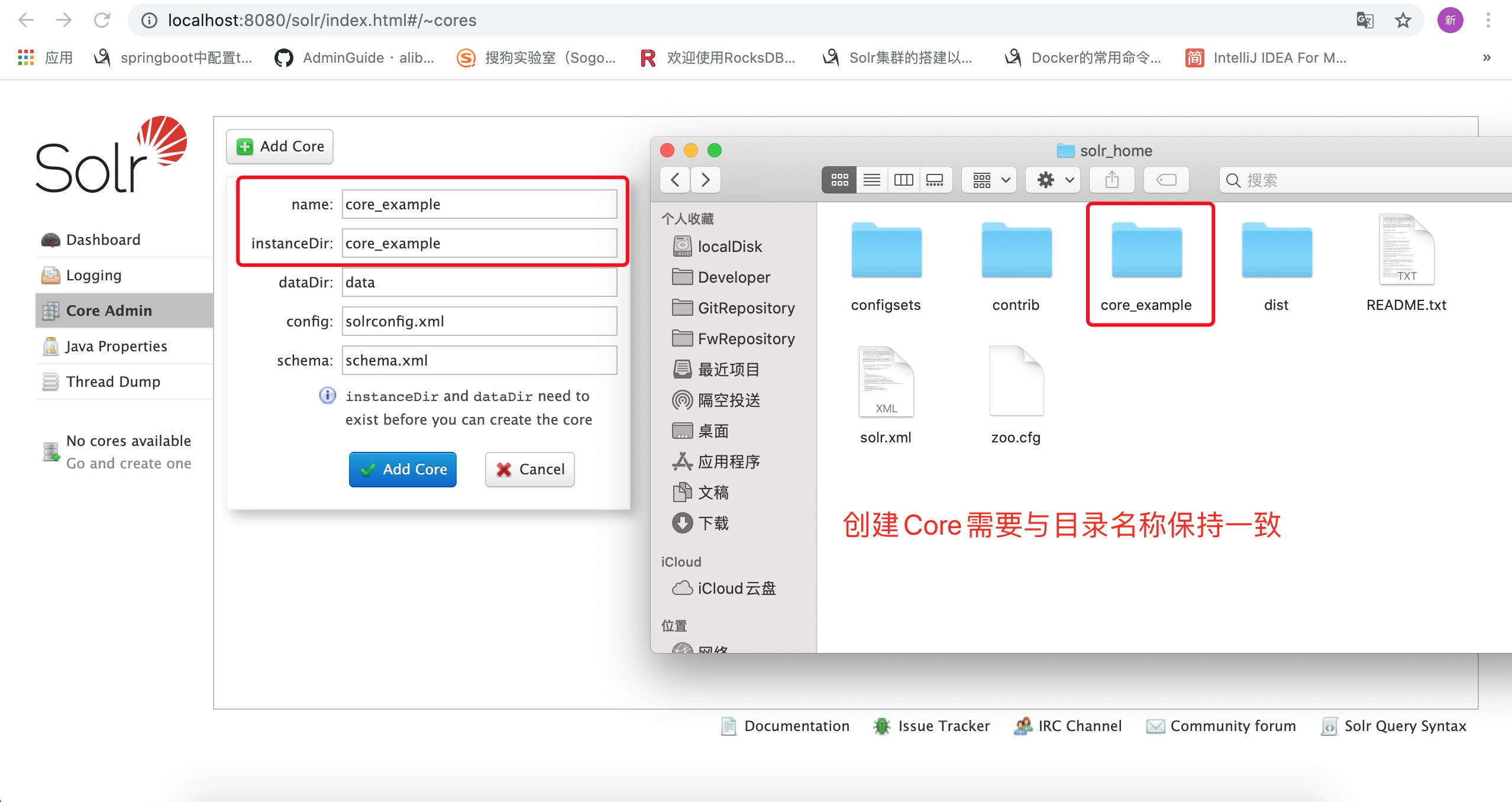
(1). 创建Core
Core类似于DB.
(2). 添加相应依赖
导入MySQL数据到Solr前,需要添加相应的依赖
# 1.拷贝:
# solr-dataimporthandler-7.7.3.jar
# solr-dataimporthandler-extras-7.7.3.jar
# 到 ${TOMCAT}/webapps/solr/WEB-INF/lib/ 目录下
lixin-macbook:solr lixin$ cp solr-7.7.3/dist/solr-dataimporthandler-* apache-tomcat-8.5.54/webapps/solr/WEB-INF/lib/
# 2.下载mysql jar包拷贝到:${TOMCAT}/webapps/solr/WEB-INF/lib 目录下
cp mysql-connector-java-5.1.42.jar ~/Developer/solr/apache-tomcat-8.5.54/webapps/solr/WEB-INF/lib/
# 3.拷贝solr自带的分词器jar包到:${TOMCAT}/webapps/solr/WEB-INF/lib 目录下
# solr-7.7.3/contrib/analysis-extras/lucene-libs目录下,包含如下jar包内容:
# lucene-analyzers-icu-7.7.3.jar
# lucene-analyzers-morfologik-7.7.3.jar
# lucene-analyzers-opennlp-7.7.3.jar
# lucene-analyzers-smartcn-7.7.3.jar
# lucene-analyzers-stempel-7.7.3.jar
lixin-macbook:solr lixin$ cp -rf solr-7.7.3/contrib/analysis-extras/lucene-libs/*.jar apache-tomcat-8.5.54/webapps/solr/WEB-INF/lib/
(3). 配置中文分词器(managed-schema)
vi solr_home/core_example/conf/managed-schema
添加以下配置信息到managed-schema文件的</schema>节点之前
可参考: https://www.cnblogs.com/miye/p/10716338.html
<!-- 配置smartcn中文分词器 -->
<!-- text_smartcn代表分词器名称 -->
<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
(4). Field详解
参考: https://blog.csdn.net/mine_song/article/details/58065323
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
name: 指定域的名称(自定义)
type: 指定域的类型
indexed: 是否索引
是:(将分好的词进行索引,索引的目的,就是为了搜索)
否:不索引,也就是不对该field域进行搜索.
stored: 是否存储
是:在检索时:在搜索页面,以及查询条件都能显示该Field域的值.
否:在检索时:搜索页面,没法获取该field域的值(仅仅只能当作查询条件来使用).
required: 是否必须
multiValued: 是否多值,比如查询数据需要关联多个字段数据,一个Field存储多个值信息,必须将multiValued设置为true.
(5). dynamicField配置详解
<dynamicField name="*_is" type="pint" indexed="true" stored="true" multiValued="true"/>
name为*_is,定义它的type为int,那么在使用这个字段的时候,任何以_is结果的字段都被认为符合这个定义
(6). uniqueKey配置
id是在Field标签中已经定义好的域名,而且该域设置为required为true.一个managed-schema文件中必须有且仅有一个唯一键.
<uniqueKey>id</uniqueKey>
(7). copyField配置
copyField复制域
比如:我们在搜索时比如输入:hello时,一篇文章分为:标题、简介、内容等很多字段,输入的关键字不可能只在一个域中进行检索,可能要在多个域中进行检索.所以出现copyField域,把多个域关联成一个域.
# 定义普通域
<field name="title" type="text_gen_sort" indexed="true" stored="true" multiValued="true"/>
<field name="author" type="text_gen_sort" indexed="true" stored="true" multiValued="false"/>
<field name="text" type="text_general" indexed="true" stored="false" multiValued="true"/>
# 定义复制域
# source : Field域的名称
# dest : 是目标域的名称
# 当检索text域时,会分别到:title和author域中进行检索
<copyField source="title" dest="text"/>
<copyField source="author" dest="text"/>
(8). fieldType
域类型
<fieldType name="string" class="solr.StrField" sortMissingLast="true" />
<fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/>
<fieldType name="pint" class="solr.IntPointField" docValues="true"/>
<fieldType name="pfloat" class="solr.FloatPointField" docValues="true"/>
<fieldType name="plong" class="solr.LongPointField" docValues="true"/>
<fieldType name="pdouble" class="solr.DoublePointField" docValues="true"/>
<fieldType name="pints" class="solr.IntPointField" docValues="true" multiValued="true"/>
<fieldType name="pfloats" class="solr.FloatPointField" docValues="true" multiValued="true"/>
<fieldType name="plongs" class="solr.LongPointField" docValues="true" multiValued="true"/>
<fieldType name="pdoubles" class="solr.DoublePointField" docValues="true" multiValued="true"/>
<fieldType name="pdate" class="solr.DatePointField" docValues="true"/>
<fieldType name="pdates" class="solr.DatePointField" docValues="true" multiValued="true"/>
<fieldType name="binary" class="solr.BinaryField"/>
(9). 分词器
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
name : 指定域类型(fieldType)名称
class : 指定域对应的solr类型
analyzer : 指定分词器
type : index/query 分别指定搜索和索引时的分析器
tokenizer : 指定分词器
filter : 指定过滤器
